Bignews 新闻检索系统文档
本文档可以通过 http://www.hikean.com/bignews/ 在线阅读。
0 项目成员
| 成员 | 院所 | 学号 | 分工 |
|---|---|---|---|
| 胡耀康 | 计算技术研究所 | 201628013229059 | 项目架构、索引构建及Web后端 |
| 谭 瑶 | 计算技术研究所 | 201628013229061 | 基于scrapy爬虫编写 |
| 徐 鹏 | 计算技术研究所 | 201628013229065 | Web前端及搜索结果聚类 |
| 唐天奇 | 计算技术研究所 | 2016E8013261182 | 自动补全、关键词推荐及相关文档编写 |
1 概述
本项目是一个基于 ElasticSearch 和 Django 框架的新闻搜索引擎,能够通过搜索关键词检索相关新闻、提示相似关键词、进行相似新闻的聚类。
可以通过 bignews.hikean.com 访问我们的新闻检索网站。

1.1 需求描述
本项目需要实现的目标是:
- 搜索
- 按相关度排序
- 按时间排序
- 按热度排序
- 输入搜索关键词自动补全
- 相似关键词的推荐
- 相似新闻的聚类
1.2 整体设计方案
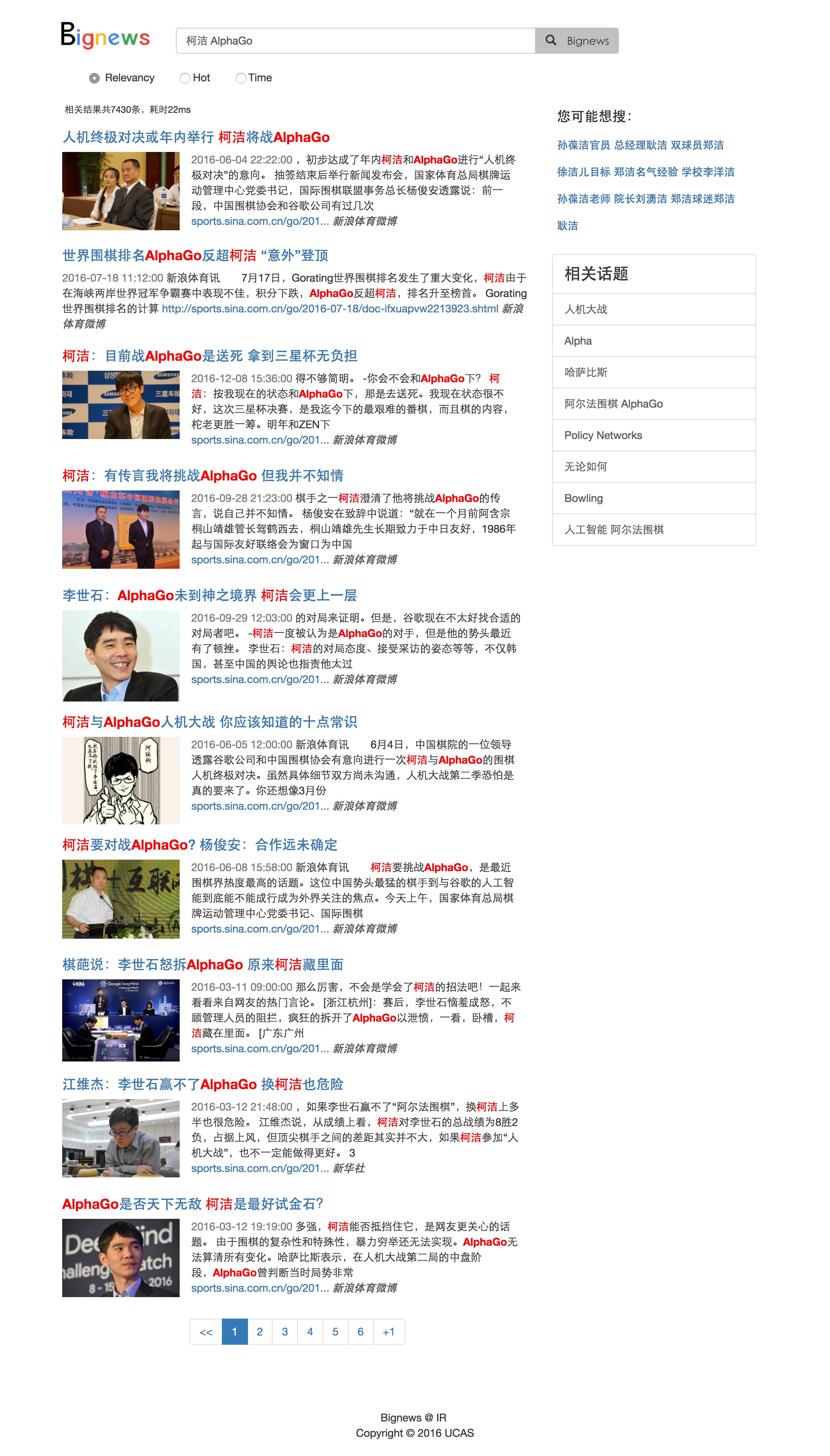
系统框架图如下:
整体实现步骤如下:
- 首先从不同的新闻网站上爬取新闻标题、内容、链接等信息,存储到本地 MySQL 数据库中。
- 使用 ElasticSearch 框架做搜索,需要建立索引,并将数据库里的信息导入 ElasticSearch,以便后续调用相关接口实现搜索功能。
- 另一方面,用 MySQL 中的原始数据做分词及后续的处理,提取出关键句,作为自动补全的候选句,并统计频次作为该候选句的权重。
- 用户在 web 端输入关键词,发送请求到后端,后端发送请求到 ElasticSearch 获得返回数据,将返回的原始数据做处理后再返回给 web 端显示给用户。
- 用户在 web 端输入关键词,发送请求到后端,后端以关键词为前缀,在之前处理的自动补全的候选句中做前缀匹配,并根据权值排序,返回前 5 条结果。
- 相似新闻聚类
2 爬取新闻数据
这里我们使用了 scrapy 框架来做爬取网页信息,并将爬取到的数据存储到本地 MySQL 数据库。
在本项目中共爬取了来自虎扑的新闻数据 22 万余条、搜狐的新闻数据 122 万余条、新浪的新闻数据 24 万余条,共计 166 万余条新闻数据。
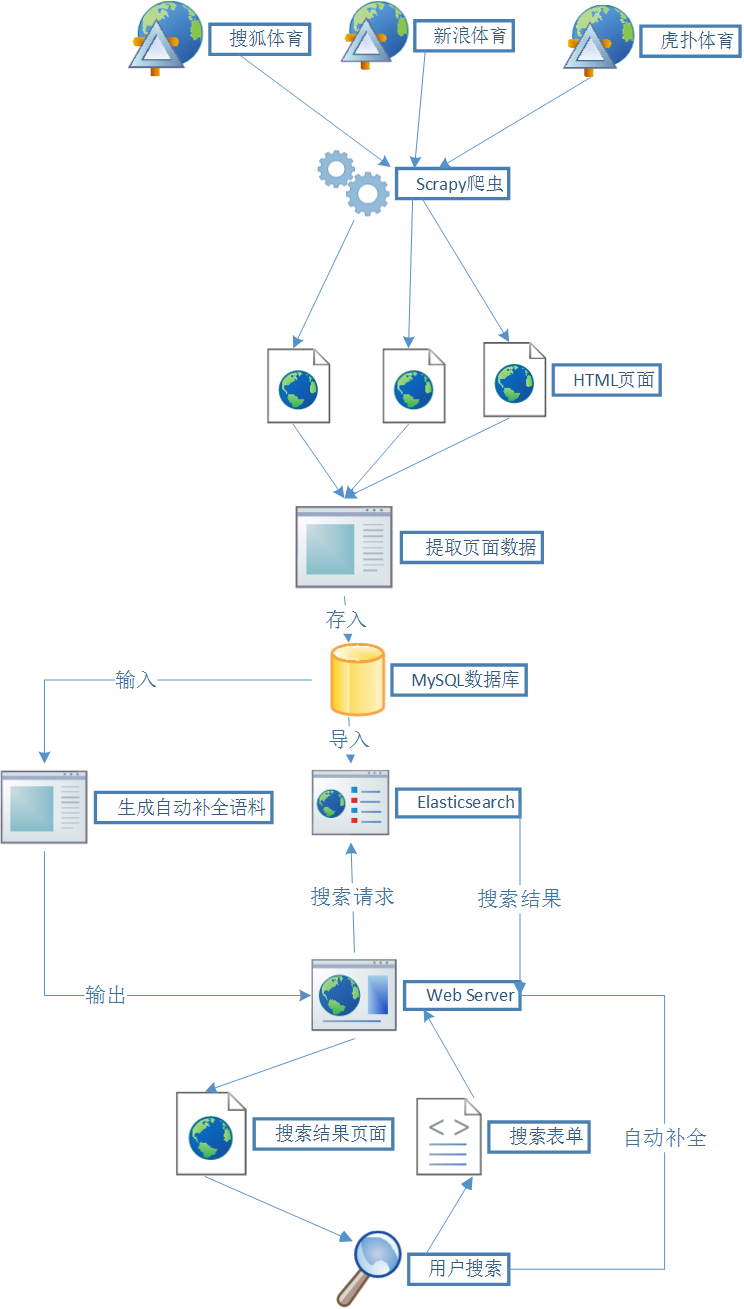
2.1 scrapy 简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
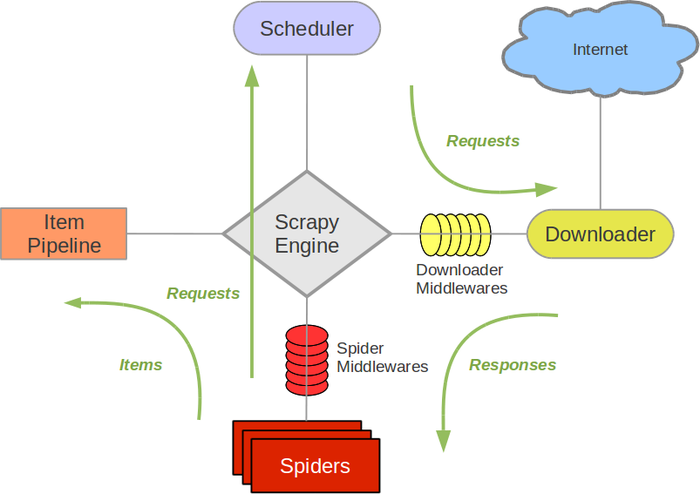
其最初是为了抓取网页所设计的,但也可以应用在获取 API 所返回的数据(例如 Amazon Associates Web Services) 或者通用的网络爬虫中。
2.2 使用 scrapy 爬虫
一般来说,使用 scrapy 进行网页抓取有如下步骤:
首先定义需要爬取的数据格式
通过 scrapy Items 来定义 Item:
class HupuItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
content = scrapy.Field()
editor = scrapy.Field()
tags = scrapy.Field()
source = scrapy.Field()
publish_time = scrapy.Field()
comment_count = scrapy.Field()
content = scrapy.Field()
further_reading = scrapy.Field()
在本项目中,我们提取了新闻网页的标题、url、内容、作者等 10 个数据段。
编写提取数据的 spider
编写一个 spider,包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容,提取生成 item 的方法。
为了创建一个 spider,您必须继承 scrapy.Spider 类,且定义以下三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
scrapy 提取数据有自己的一套机制。它们被称作选择器(seletors),因为他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在 XML 文件中选择节点的语言,也可以用在 HTML 上。 CSS 是一门将 HTML 文档样式化的语言。选择器由它定义,并与特定的 HTML 元素的样式相关连。
XPath 表达式的例子和含义:
/html/head/title: 选择HTML文档中 <head> 标签内的 <title> 元素
/html/head/title/text(): 选择上面提到的 <title> 元素的文字
//td: 选择所有的 <td> 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
运行 spider 并保存数据
例如,我们定义的 spider 的 name = ‘hupu’,那么运行:
scrapy crawl hupu -o scraped_data.json
即可将爬取数据存到 scraped_data.json 中。
但为了方便后面使用,这里我们通过 item pipelines 直接将数据存储到数据库。
3 构建搜索引擎
3.1 ElasticSearch
简介
ElasticSearch 是一个基于 Lucene 的实时搜索和分析引擎。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。
Elasticsearch 使用 Lucene 作为内部引擎,在使用它做全文搜索时,只需要使用统一开发好的 API 即可,而并不需要了解其背后复杂的 Lucene 的运行原理。
当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
建立索引、导入数据
在本项目中,我们使用 python 的 elasticsearch 包来和 ElasticSearch 的 RESTful API 进行通信。其通信数据使用 json 格式。
在 Elasticsearch 中,文档属于一种类型(type),各种各样的类型存在于一个索引(index) 中。我们可以通过类比传统的关系数据库得到一些大致的相似之处:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。
首先,我们要建立一个名为 news 的索引,表示我们后续将在这个 index 下插入数据,进行查询等操作。
# 表示以elastic为用户名 password为密码 在本地创建了名为news的索引
curl -XPUT http://elastic:password@localhost:9200/news
接下来,我们要建立一个类型名称为 hupu 的映射(_mapping),_mapping 详细的描述了 hupu 类型的文档各种属性:
curl -XPOST http://elastic:password@localhost:9200/news/hupu/_mapping -d'
{
"hupu": {
"_all": { // 默认全文字段,使用ik_max_word进行分词
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"term_vector": "no",
"store": "false"
},
"properties": { //hupu类型的文档的全部属性
"title": {
"type": "text",
"include_in_all": "true",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"boost": 3
},
"url": {
"type": "keyword"
},
"editor": {
"type": "keyword"
},
"tags": {
"type": "keyword",
"boost": 5
},
"suggest":{
"type": "completion",
"analyzer": "ik_smart"
},
"source": {
"type": "keyword"
},
"publish_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"include_in_all": "true",
"boost": 1
},
"further_reading": {
"type": "keyword",
"index": "not_analyzed"
},
"comment_count": {
"type": "long"
}
}
}
}'
接下来,我们可以向索引中导入数据,连接本地的 ElasticSearch 服务,向相应索引发送插入数据请求:
def test_import_data():
es = Elasticsearch(['http://localhost:9200/'])
cursor.execute("SELECT * FROM hupu2")
for row in cursor:
doc = dict(zip(cols_name, row))
doc["publish_time"] = str(doc["publish_time"])
doc["suggest"] = [ x for x in doc["tags"].split("||") if x and x != ""]
doc["suggest"].append(doc["title"].split("_")[0])
doc["title"] = doc["title"].split("_")[0]
doc["content"] = "".join(row[-2].strip().split(" ")[:-2])
try:
res = es.index(index="news", body=doc, doc_type="hupu", id=re.findall(r'([0-9]+)', doc["url"])[0])
except:
print doc
建好索引,导入数据,即可对 ElasticSearch 发送请求,使用其搜索、聚类等功能。
3.2 搜索排序
这里我们可以按照相关性(relevancy)、热度(hot)和时间(time)对搜索结果进行排序。
body = {
"min_score": 5,
"query": {
"multi_match": {
"query": keywords,
"fields": ["content^5", "title"]
}
},
"highlight": {
"pre_tags": ["<b style=\"color:red;\">"],
"post_tags": ["</b>"],
"fields": {
"content": {},
"title": {}
}
},
"sort": [
{"_score": {"order": "desc"}}
],
"from": (now_page - 1) * 10,
"size": 10
}
# 默认按照相关度排序
# 根据时间排序,同时需要考虑到相关度,因此不能完全按照时间排序
# 这里按照"doc['publish_time'].value/864000000"进行排序
# 即将时间除以约为7天的时间,使时间相邻7天内的数据集内部是按相关度排序的,然后再按这个弱化后的时间排序
if rank == "time":
body["min_score"] = 30
body["sort"] = [{"publish_time": {"order": "desc"}}, {"_score": {"order": "desc"}}]
body["sort"] = [
{"_script": {"type": "number", "script":
{"lang": "painless", "inline": "doc['publish_time'].value/864000000",
"params": {
"factor": 0.5
}}, "order": "desc"}},
{"_score": {"order": "desc"}}]
# 热度我们定义为 一条新闻的评论数*该新闻的权值
# 根据这个热度定义进行排序
elif rank == "hot":
body["sort"] = [
{"_script": {"type": "number", "script":
{"lang": "painless", "inline": "doc['comment_count'].value * _score",
"params": {
"factor": 0.5
}}, "order": "desc"}},
{"_score": {"order": "desc"}}]
try:
content = es.search(index="news", body=body)
3.3 聚类
carrot2 是一个开源搜索结果聚类引擎。本项目中用到的是在 ElasticSearch 中的 carrot2 插件,可以自动地将相似的文档组织起来,并且给每个文档的群组分类贴上相应的较为用户可以理解的标签。这样的聚类也可以看做是一种动态的针对每个搜索和命中结果集合的动态 facet。可以在Carrot2 demo page体验一下这个工具。 每个需要聚类的文档有若干逻辑单元:文档标识符,原始的 URL,标题,主要的内容和语言代码。只有标识符字段是强制的,其他部分都是可选得,但是至少一个其他字段是需要指定以保证操作的合理性的。 在 Elasticsearch 中索引的文档不需要按照任何的预设 schema 所以一个 JSON 文档的实际字段需要被映射到聚类插件要求的逻辑单元上。下面图示了一个例子:
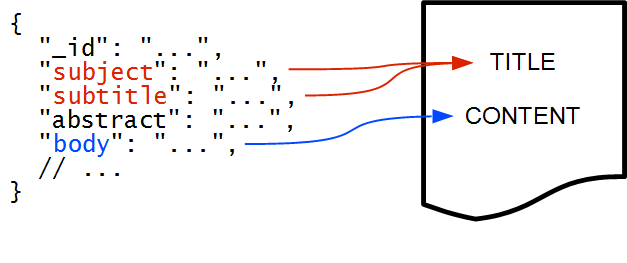
请注意文档的两个字段被映射到 TITLE 上。这不是一个错误,任意数目的字段都可以映射到 TITLE 或者 CONTENT 上——这些字段的内容可以被连接起来用作聚类。 逻辑单元也可以用生成的内容进行填充,例如使用高亮在文档的字段上。这功能可以大大降低输入给聚类算法的文档数量(提高性能),同样会让聚类的内容更加与查询相关(聚类效果更佳)。
在本项目中,将搜索结果返回的前 100 条做聚类,根据建立的索引,使用 lingo 算法聚类。相关代码如下:
def _do_cluster(keywords, algorithm="lingo", size=100, topic_count=10):
if not algorithm or not size:
return []
body = {
"search_request": {
"fields": ["title", "content", "url"],
"query": {
"match": {
"_all": keywords
}
},
"size": size
},
"query_hint": "",
"field_mapping": {
"title": ["fields.title"],
"content": ["fields.content"],
"url": ["fields.url"]
},
"algorithm": algorithm
}
try:
r = requests.post('http://localhost:9500/_search_with_clusters/', data=json.dumps(body))
except:
return None
return format_cluster_response(r.json(), topic_count)
4 搭建Web应用
我们使用了 Django 框架搭建 Web 应用。
4.1 Django
简介
Django 是一个开放源代码的 Web 应用框架,由 Python 写成。采用了 MVC 的框架模式,即模型 M,视图 V 和控制器 C。这套框架是以比利时的吉普赛爵士吉他手 Django Reinhardt 来命名的。
Django 是一个基于 MVC 构造的框架。但是在 Django 中,控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),称为 MTV 模式。
一次 Web 访问的实质
客户发送http请求到web服务器,web服务器返回html页面给用户。逻辑结构图如下:
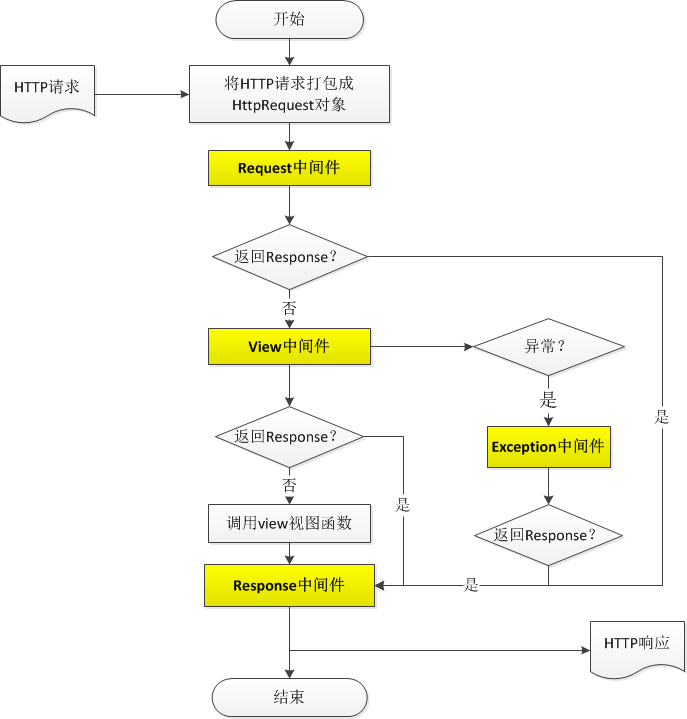
搭建一个 newsweb
首先,我们创建一个 Django 项目,安装完毕后,运行:
django-admin startproject newsweb
即创建了项目,项目目录如下:
├-- newsweb
| |-- __init__.py
| |-- settings.py
| |-- urls.py
| └─- wsgi.py
└─- manage.py
其中,
manage.py: 大管家。管理整个后台,包括建立数据库、运行服务器、测试等。
settings.py: 配置文件。
urls.py: URL映射配置文件。当访问一个url时,决定该url访问被哪个程序(函数)响应,从而返回生成不同的页面。
wsgi.py: python应用程序或框架与web服务器之间的接口。
然后我们需要创建一个应用,用来实现具体的功能,运行:
python manage.py startapp search
即创建了名为 search 的应用,./newsweb/search 目录如下:
├── __init__.py
├── admin.py
├── apps.py
├── migrations
│ └── __init__.py
├── models.py
├── tests.py
└── views.py
其中,
views.py: 响应客户请求,进行相关的逻辑处理,返回html页面。
models.py: 定义数据库相关内容。但是我们这里只用从本地数据库取数据就可以了,不需要用到这个。
admin.py: 给django自带的admin应用来辅助使用。admin应用是管理数据库后台的工具。
test.py: 测试相关。
介绍具体功能实现时会贴出必要的代码。
4.2 autocomplete
autocomplete 功能指的是在搜索框输入需要查询的关键字时,在用户输入时弹出下拉框提示用户可能想输入的候选关键字。
这里我们首先需要处理出候选关键字的集合,然后在用户输入时,前端监听 change 事件,当输入框有变化时,自动发送请求到后端,后端根据用户输入的关键字,在候选关键字中进行前缀匹配,找到相匹配的权重最高的 5 条记录,然后返回给前端显示给用户。
处理候选关键词集合时,我们先用 jieba 分词处理全部新闻数据,根据词性,留下每个文档中每个句子中的名词和动词,并限制长度,组成候选关键词。处理完全部文档之后,统计所有候选关键词出现的频率,并存储相应拼音以便索引。
当后端收到用户请求时,根据全拼或汉字在候选词库中进行前缀匹配,前缀相同的候选词按照频率排序,并返回前 5 条数据。
views.py 中实现该部分功能代码如下:
def auto_complete(req):
prefix = req.GET.get("prefix", None)
response = []
if prefix:
body = {
"suggest": {
"prefix": prefix,
"completion": {
"field": "suggest"
}
}
}
response = format_suggest_response(es.suggest(index="news", body=body))
json_data = json.dumps({"suggestion": response})
return HttpResponse(json_data, content_type="application/json")
autocomplete 部分效果图如下:
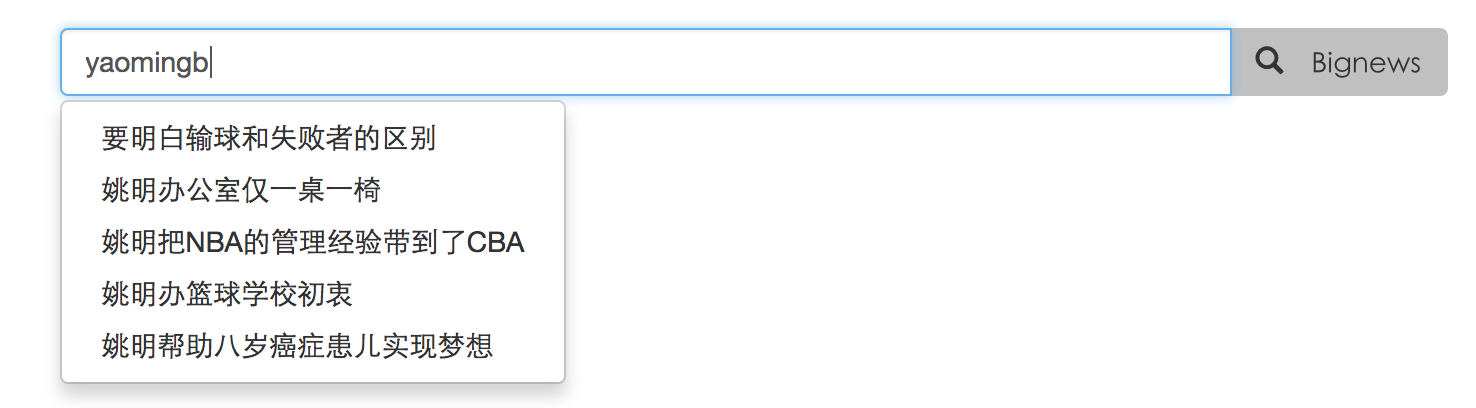
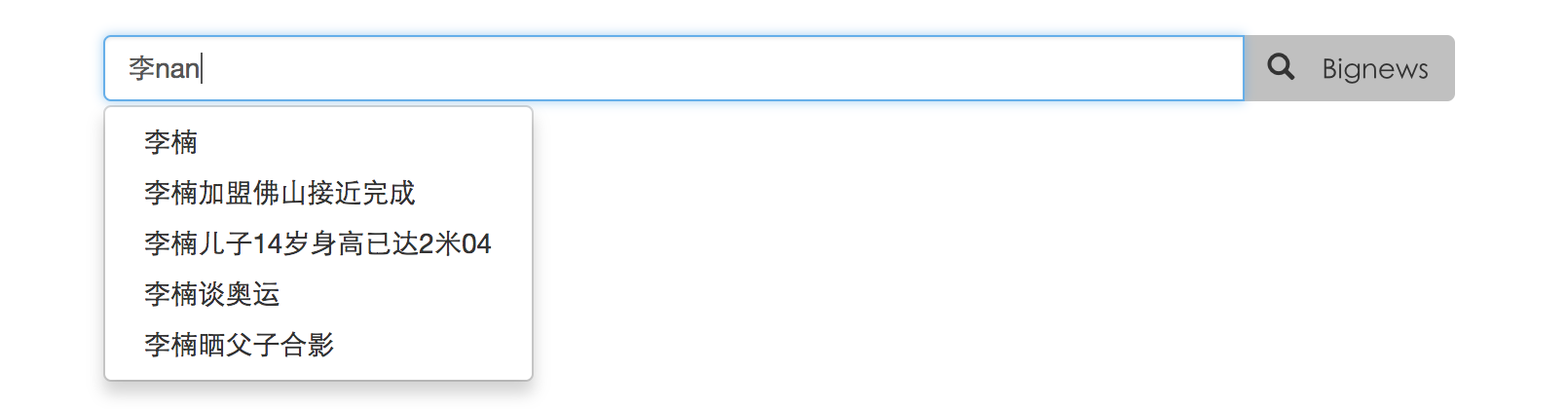
4.3 基于 word2vec 的相似关键字推荐
word2vec 是谷歌开源了一款基于 Deep Learning 的学习工具,word2vec(word to vector)顾名思义,这是一个将单词转换成向量形式的工具。通过转换,可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。
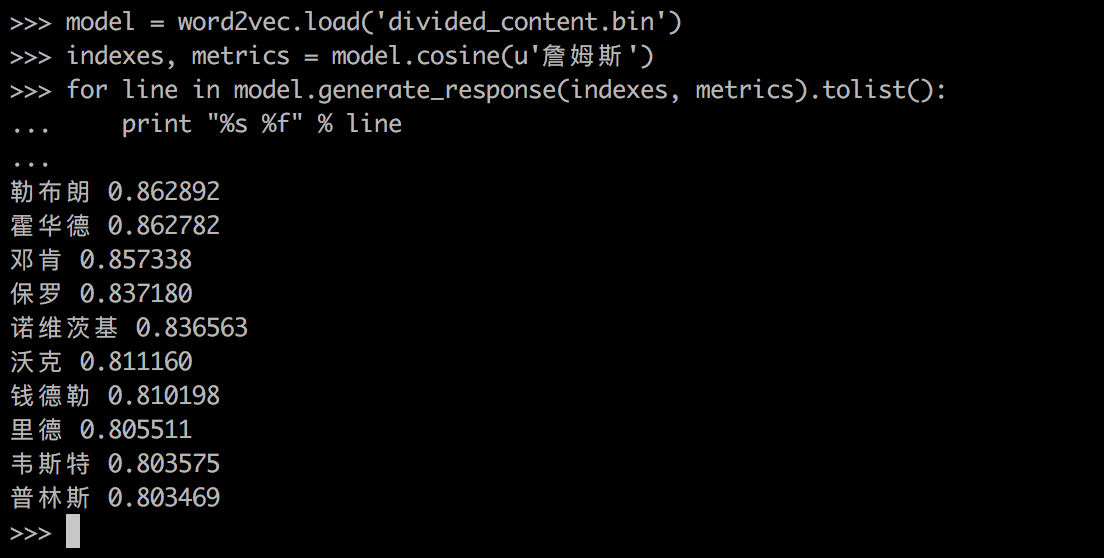
首先,我们对爬取的新闻数据做分词,再将分词后的语料用 word2vec 进行训练,word2vec 根据语料上下文关系用深度学习的方法训练,将 word 映射到空间向量。训练完毕后得到 divided_content.bin 文件,存储的是训练语料中词的信息,使用时调用该文件,根据用户输入的关键词,计算与之余弦相似度最高的词,返回前 10 条给前端推荐给用户。
但直接用 word2vec 会存在一个问题,用 word2vec 求相似关键词不支持训练出的词库里没有的词,而用户可能输入短语也可能输入句子进行查询,当用户输入的词语用 word2vec 找不到结果时。为了解决这个问题,我们将 autocomplete 中处理出来的候选词集合用 ElasticSearch 建立一个新的索引,将用户输入的关键词在新的索引中进行搜索,也就是返回与之相似度匹配最高的结果,再返回给用户。
求相似关键词的例子:

5 应用展示
- 主页、输入关键字
- 拼音自动补全
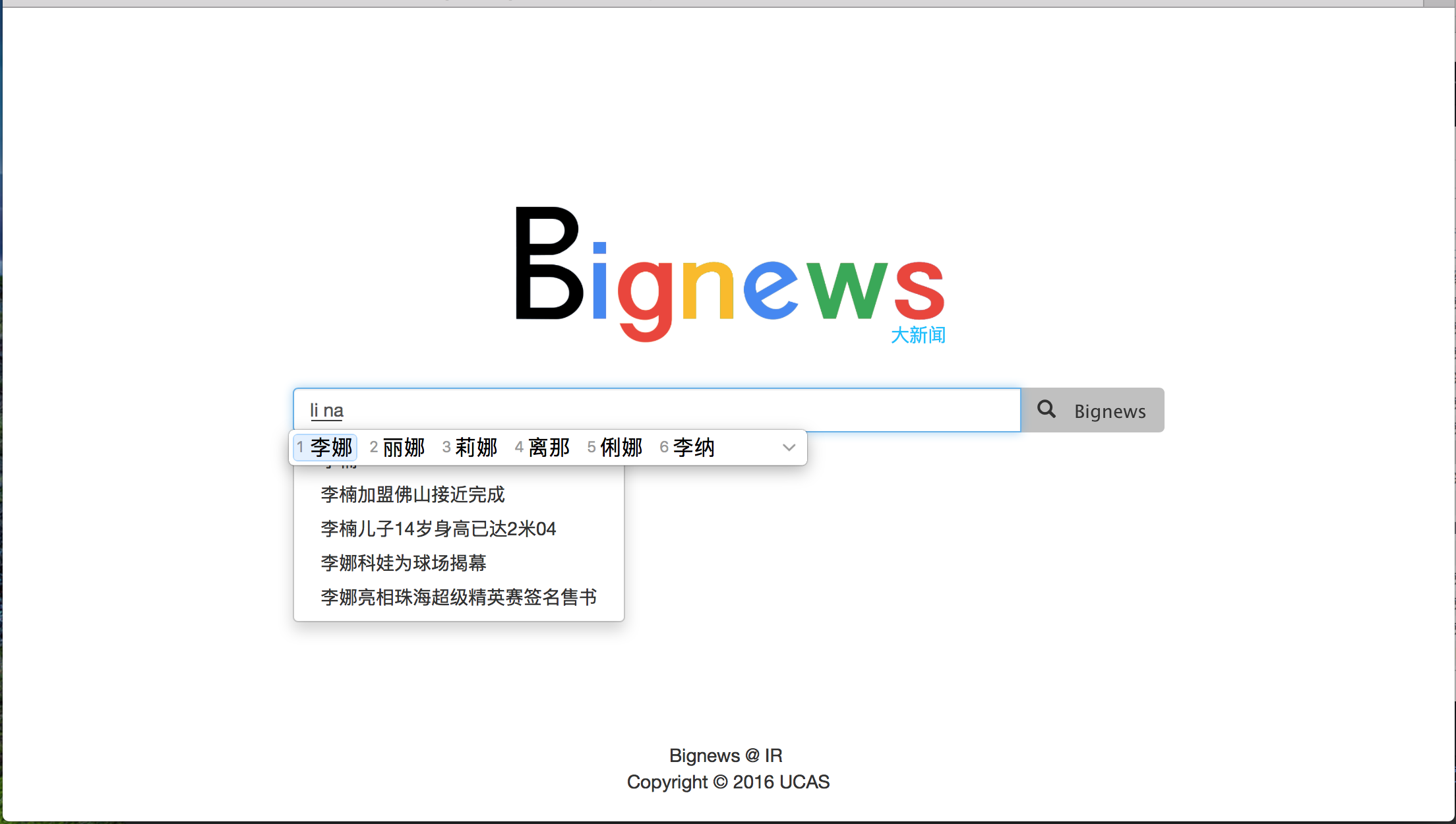
- 汉字中文混合自动补全
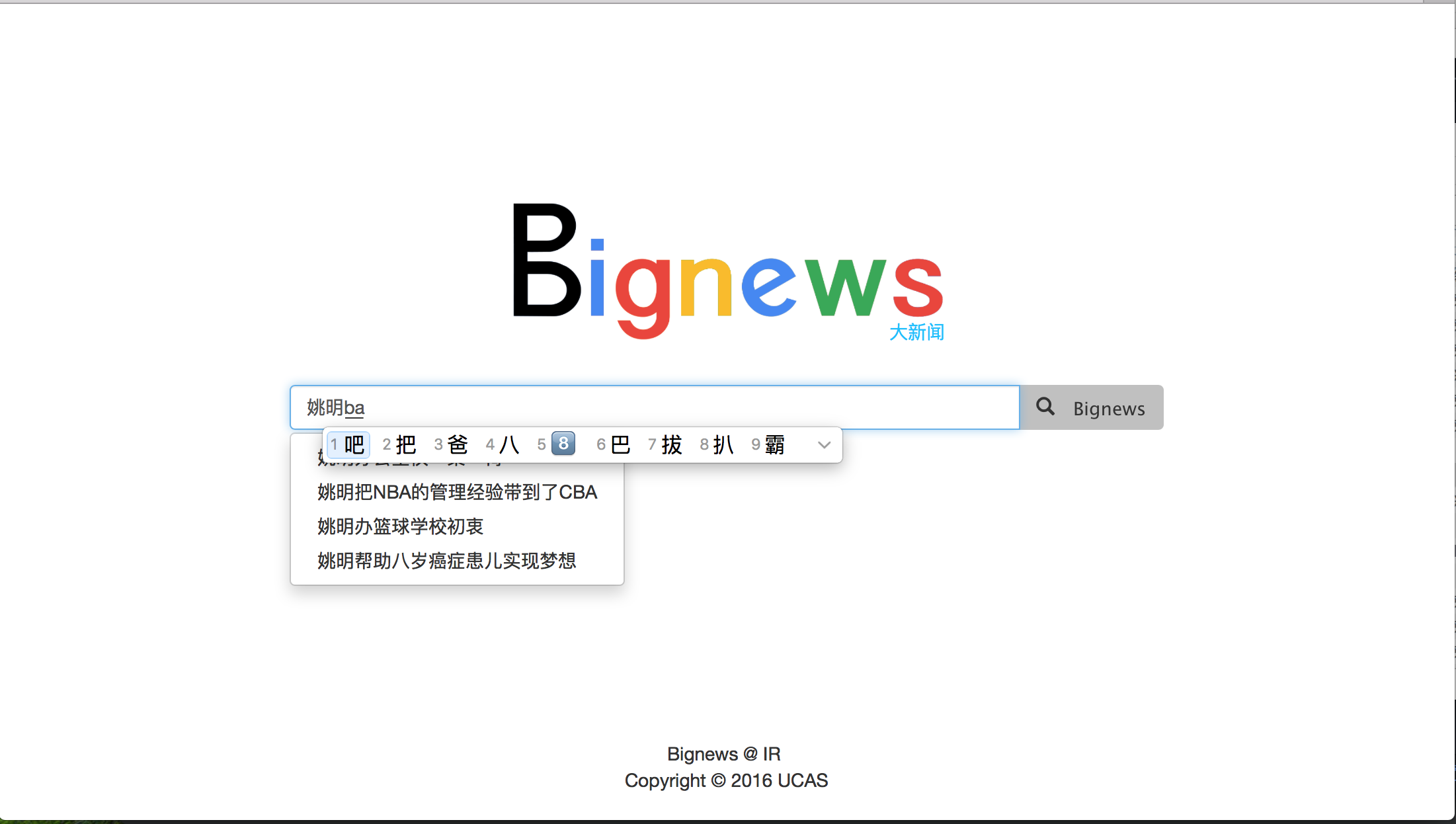
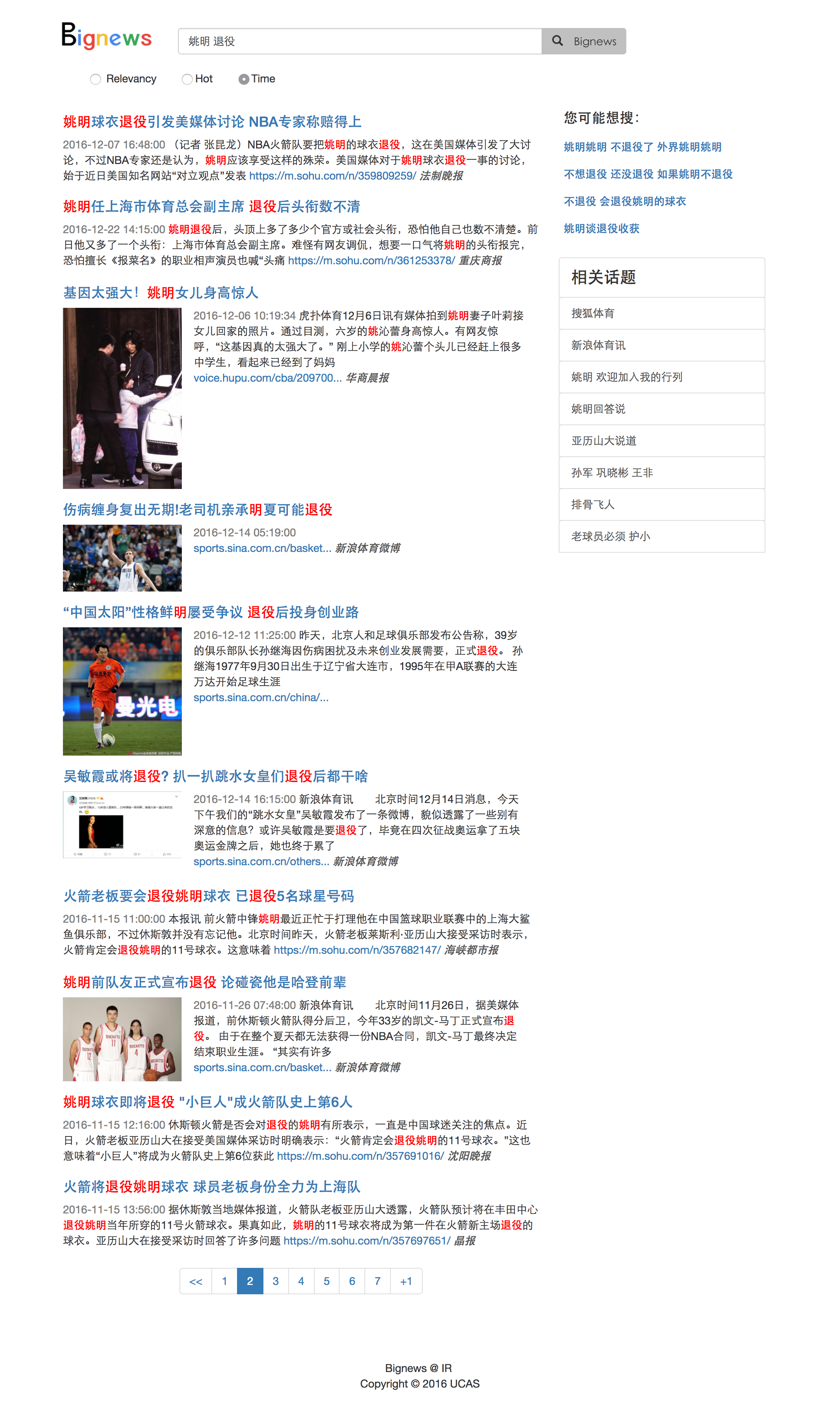
- 搜索结果、相似关键词、相似结果聚类
- 地址:http://bignews.hikean.com/search/?keywords=%E5%A7%9A%E6%98%8E

- 按热度、时间的搜索结果

总结
值得改进之处
-
autocomplete 功能不太适用于现在的互联网搜索
现在的互联网上常用的搜索引擎大多是根据用户搜索关键词的频率来进行排序,并推荐给用户关键词。而且还会考虑到拼音、简拼,不仅仅是简单的前缀匹配。 而且该功能是基于预处理好的语料库,实际在服务器上比较占资源。
-
聚类中心不好控制
-
按时间排序采取的模糊时间的方法,使得搜索结果的相关度大大降低了
总结
在本项目中,我们使用了目前较为流行和创新的技术和框架,包括 ElasticSearch、Django、MySQL、Scrapy、word2vec、Carrot2、Bootstrap、jieba、ik 分词等,避免重复造轮子的同时,结合课本知识学习了这些技术框架的工作原理,了解了前人是如何解决文本处理、信息检索方面的问题,也认识了许多在过程中优化的方法、可以改进的地方。